
前两篇:
(一)前言&RPC
(二)SOAP
(三)REST
(四)GraphQL(Next?)
Talk is cheap. Show me the code.
先放个GraphQL的代码,在这里。(竟然是一个月前的代码了,写文章还是不能拖拉啊)
如同上一篇文章所说,REST是现在API设计的绝对主流思想,但也不是没有缺点的。比如太多的HTTP请求,抓取了过多的信息等。当然,现在有好多各种各样的框架、协议尝试对REST做一些改进。比如HAL、Swagger、OData JSON API。(以上几个都可以花时间浏览下,还是很有启发的)
还有很多小的工程或者项目的内部工具都是为了更加爽快的使用REST而诞生的。我不想一一列举这些工具,这里只是从设计角度,假设我们自己要设计一个基于REST的改进工具,我们会对这个工具有那些要求:
1.最小化HTTP请求数量
每个HTTP请求都是有代价的,握手、延迟、解析甚至如果在移动平台上过多HTTP请求对手机电池的消耗都是必须考虑的。理想情况下,我们的新API设计,需要允许客户端需要有能力在最小的HTTP请求数中,得到需要的数据。
2.最小化payload
和上个目标一样,受限于带宽、CPU、内存等等因素,理想情况下,我们的新API设计,需要能够发送且只发送客户端需要的最小数据。当然,为了实现这个目标,客户端需要有能力描述要求的数据内容。
3.可读性要强
从SOAP中获取的教训,API的交互要简单。对程序员来说,如果能用curl、wget或者类似的简单工具直接交互才是最好的。
4.类型支持
另外一个我们从RPC和SOAP中学到的教训是,服务器和客户端之间的协议(contracts)非常有用。因为如果用JSON的话,所有字段本质上都是string类型传输的,如果有强类型系统(type systems)来做检测就更好了。顺便一提,这也是为什么我一直支持typescript开发nodejs系统的原因,在正式、多人的项目里,强类型系统对开发的帮助是在是太重要了。
比如说,我们可以定义博客的数据结构:
type posts {
title:String
description:String
create_date:Date
tags:[String]
author:User
}
5.查询语言的支持
多年来,设计大型系统时一个非常重要的原则就是“separation of concerns”。然而,不幸的是,大部分系统,最后都变成了拥有一个暴复杂逻辑的中央数据层的怪物。假设子系统A、B、C需要用户数据,但是他们对数据的形状什么的都有各自的特殊要求。理想的设计是提供一个统一的,支持对数据的形状进行裁剪、过滤的接口。这么看来,一种简单的查询语言是最符合我们要求的。
理论上SQL是符合我们的要求的,唯一的问题是SQL太复杂,而且和基本上已经成为事实数据格式标准的JSON不是太友好。我们可以考虑类似mongodb的做法,以选择特定field为例:
select title,description from posts; // SQL
db.posts.find(
{ },
{ title: 1, description: 1, _id: 0 }
) //mongodb
所以,我们的新查询语言可以是这样的:
{
posts {
title
description
author {
name
}
}
}
恩,事实上,上面的简单类型系统加上这个简单的查询语言,就是GraphQL了。记住,GraphQL只是一个specification,只是一个规格定义,并不牵涉到任何具体的语言、实现、客户端。在我的这个小例子里面,语言上我用了typescript,框架上用了express,数据库只是内存里的一个数组而已。
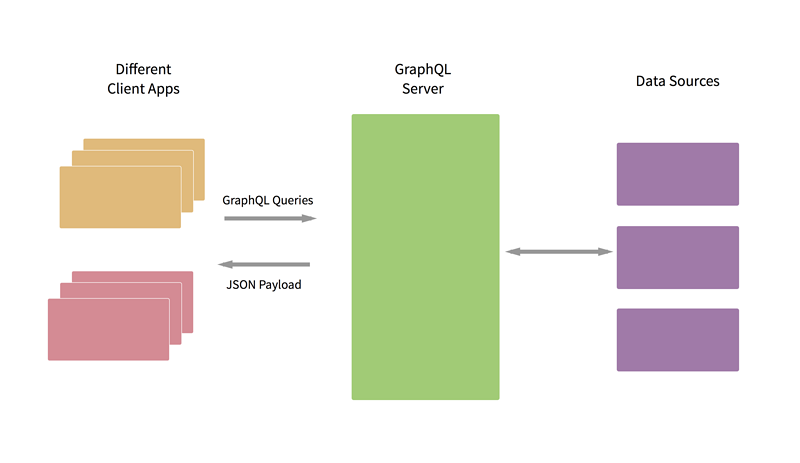
引入GraphQL并不意味着需要改写现有的系统接口,GraphQL可以看做一个前端和后端之间的灵活有效的业务逻辑层。后面的数据源可以是一个SQL数据库、一个Microservice、甚至是另外一个API。
对代码的一些说明:
// check auth here
let checkAuth = (req, res, next) => {
// console.log(req.headers.jwt);
next();
};
app.use('/graphql', checkAuth, graphqlHTTP({
schema: schema,
// rootValue: root,
graphiql: true //Set to false if you don't want graphiql enabled
}));
实现了一个简单的权限校验函数checkAuth,引入了schema定义,在/graphql开放了网页版测试客户端。
export const UserType = new GraphQLObjectType({
name: "user",
fields: {
id: {
type: new GraphQLNonNull(GraphQLInt),
description: "id of user"
},
username: {
type: new GraphQLNonNull(GraphQLString),
description: "username of user"
},
password: {
type: new GraphQLNonNull(GraphQLString),
args: {
"hide": {
type: GraphQLBoolean,
defaultValue: true
}
},
description: "password of user, default is hide",
resolve: (_, { hide }) => {
if (hide) {
return "******";
} else {
return _.password;
}
}
}
}
});
用户的强类型定义,等同于官方的这种定义方式。一个比较有趣的地方是我在这个定义里面默认隐藏了密码字段的值,只有当你覆盖默认设置password(hide:false)时才会显示密码。
export let userQuery = () => ({
users: {
type: new GraphQLList(UserType),
resolve: () => {
return db;
}
},
user: {
type: UserType,
args: {
"id": {
type: new GraphQLNonNull(GraphQLInt)
}
},
resolve: (_, {
id
}) => {
return db.find(u => u.id === id);
}
}
});
定义了我们这个graphql会暴露2个查询接口,现实所有用户的users和按照id查询的单个用户查询user。

GraphQL虽然是一种强大而灵活的工具,优点已经在上面阐述过了。然而,公平的说,GraphQL也有自己的缺点:
1.数据集成和错误处理
因为很多时候,GraphQL在系统里起到了数据网关、Gateway的作用。不同的数据源如何整合、异步的数据处理、各个不同系统之间混乱的架构关系等都是不小的挑战。另外、如果后台的部分数据服务不可用,该如何报错?REST的用HTTP status code来表示状态的方法无法沿用到整合了多个后台数据源的GraphQL上。
2.Cache
高度灵活的动态查询意味着难以缓存,你可能需要使用类似Apollo提供的Cache一样,设计一套复杂的逻辑。
3.CPU消耗
解析、验证、类型检测一个查询语句是一个非常消耗CPU的动作。特别是在NodeJS这种默认单CPU的环境下面
总结:
API设计的选型对整个系统的健壮性、可扩展性是影响非常大的。挑选一个合适当前项目的设计是架构师的主要工作之一。不要把自己限制在某个特定的设计上,合适才是最重要的。如果我要给一个状态机做接口,明显RPC风格的更合适;如果大部分是数据的CRUD,那一定要用REST。如果都有,混合两种风格的API也未尝不可。
